Why FP8: Choosing the Right Qwen3.6 Quant for Agentic Coding
I replaced my local model in OpenCode from Qwen3.6-27B to Qwen3.6-35B-A3B in FP8. Here is why, and why the other two options — the smaller 27B and the NVIDIA NVFP4 variant — lost.
Benchmark Setup
Measured with llm-race using the multi-agent parallel workflow:
Multiple independent agents running in parallel — 4 agents, 12 queries, 256 prefill tokens, 4096 output tokens. Independent parallel agents with user queries and tool context.
My homelab workstation (“Tesla”) runs vLLM on a single NVIDIA RTX PRO 6000 Blackwell with 96 GB of VRAM, dedicated to me. I use OpenCode with the Oh-My-OpenAgent plugin for agentic coding — multi-step, autonomous, terminal-driven development.
The question was: which Qwen3.6 quant to run locally?
Option 1: Qwen3.6-27B-FP8
The smaller model. Closer to what I already had.
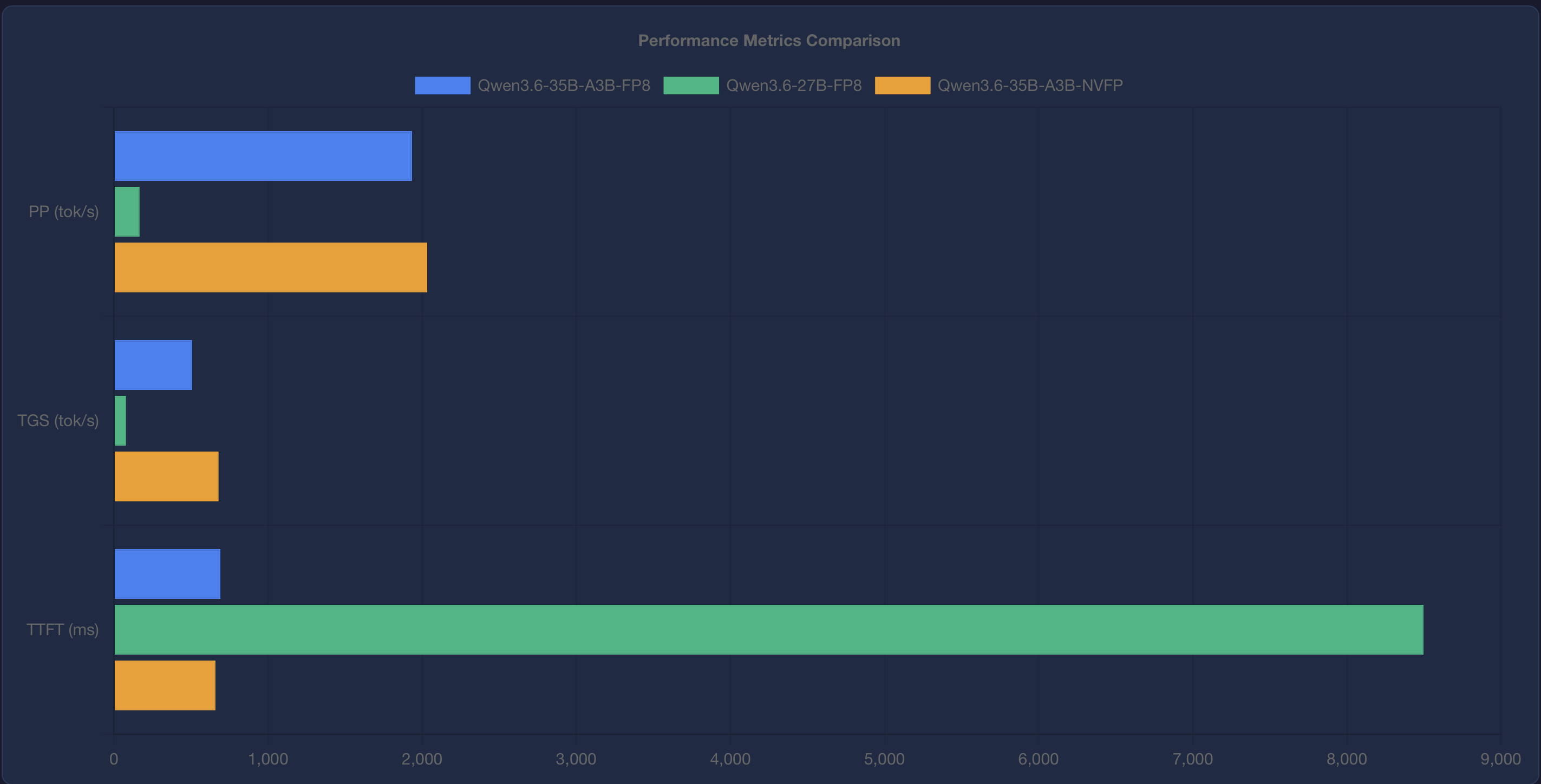
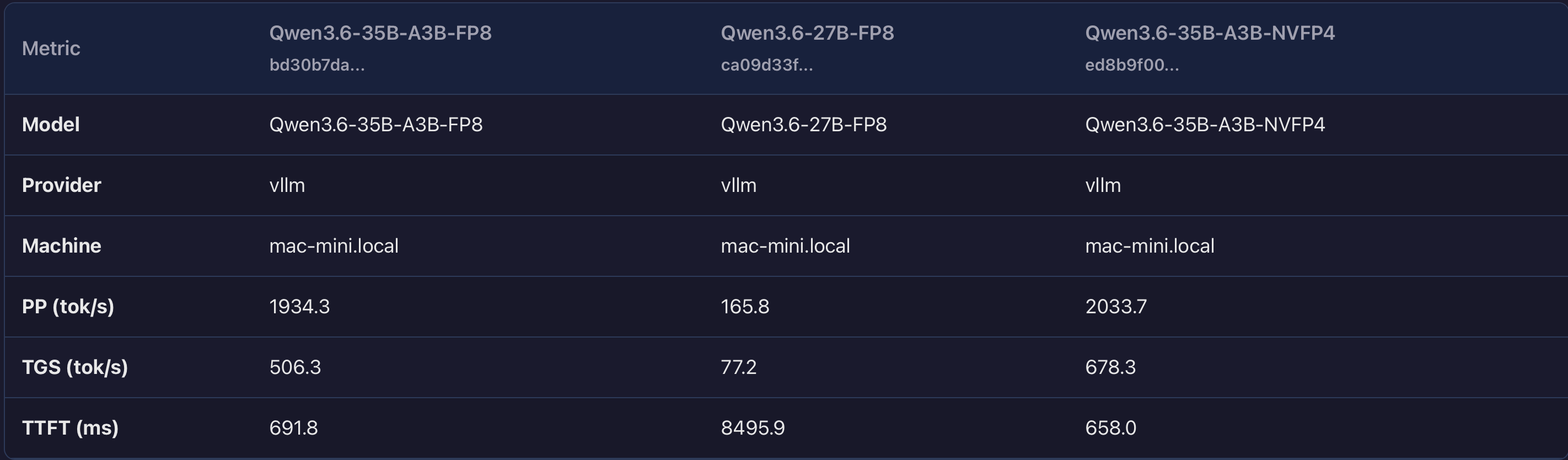
Quality: marginally lower than 35B on coding benchmarks. Not a dramatic difference, but measurable.
Speed: roughly one fifth the throughput of the 35B. On agentic workflows where the model generates 1000+ token responses, this means waiting three times longer for each turn. In interactive coding, that adds up fast.
Verdict: slower and not much different in quality. The 35B is worth the extra VRAM.
Option 2: NVIDIA’s NVFP4 Variant
Theoretically, NVFP4 offers ~2x bandwidth efficiency over FP8. Weights are smaller, transfer is faster. On paper it makes perfect sense.
In practice on Blackwell with vLLM:
- The marlin dequantization kernel consumes exactly what the smaller weights save in transfer. The theoretical bandwidth advantage evaporates at the dequant step.
- The resulting TPS difference is ~6% — roughly 1.26s vs 1.19s for a 1000-token turn. That is invisible in interactive use.
- There is a measurable quality loss in coding benchmarks compared to FP8. NVFP4 is a real quant, and even a good one, it still quantizes.
- The 17 GB of VRAM savings are irrelevant with 96 GB dedicated to a single user. You are not squeezing models onto a shared H100 server — you have the room.
- The NVIDIA kernels for sm_120 (Blackwell) are not yet mature. The NVFP4 kernels in vLLM nightly still require dequantization workarounds. The FP8 backend, by contrast, uses native Triton with real hardware FP8 support on Blackwell. Simpler, more mature, fewer edge cases.
Verdict: the 2x bandwidth advantage is theoretical. It does not materialize on Blackwell today, it costs quality, and the kernels are not ready.
Option 3: Qwen3.6-35B-A3B in FP8
Quality: highest of the three. The 35B A3B (active 3B sparse) gives the best coding performance in the family.
Speed: good. On my hardware it generates tokens at a pace that feels instantaneous during agentic workflows. The ~6% TPS advantage NVFP4 theoretically has over FP8 is not perceptible in practice.
Backend maturity: FP8 on Blackwell uses Triton natively with real hardware FP8 support. No dequantization workarounds. No nightly kernel hacks. It just works.
VRAM: 96 GB is plenty for a 35B A3B in FP8. No squeezing, no swapping, no patience-testing context limits.
The Conclusion
For this specific setup — RTX PRO 6000 Blackwell, single-user, agentic coding workflow — FP8 is the correct choice.
NVFP4 makes sense on HBM-equipped hardware (H100/H200) where the bandwidth equation is genuinely different, or when you have native NVFP4 kernels without dequantization in vLLM. Neither condition applies here.
The 27B is slower. The NVFP4 has no real speed advantage and loses quality. The 35B FP8 is the sweet spot — best quality, good speed, mature backend, and VRAM to spare.
I went back to the FP8 recipe I started with. Sometimes the simple answer is the right one.
See also: Qwen3.6 Benchmarks & vLLM Recipe — the full benchmark suite and Docker setup behind these numbers.