Yesterday, I conducted a series of local benchmarks using BenchLocal.app and a custom voicebot script. The goal was to evaluate different Qwen3.6 variants to determine the best candidate for the OpenCode project.
The tests were performed on an NVIDIA RTX PRO 6000 Blackwell Max-Q GPU. Below are the results for the four models evaluated.
Benchmark Results
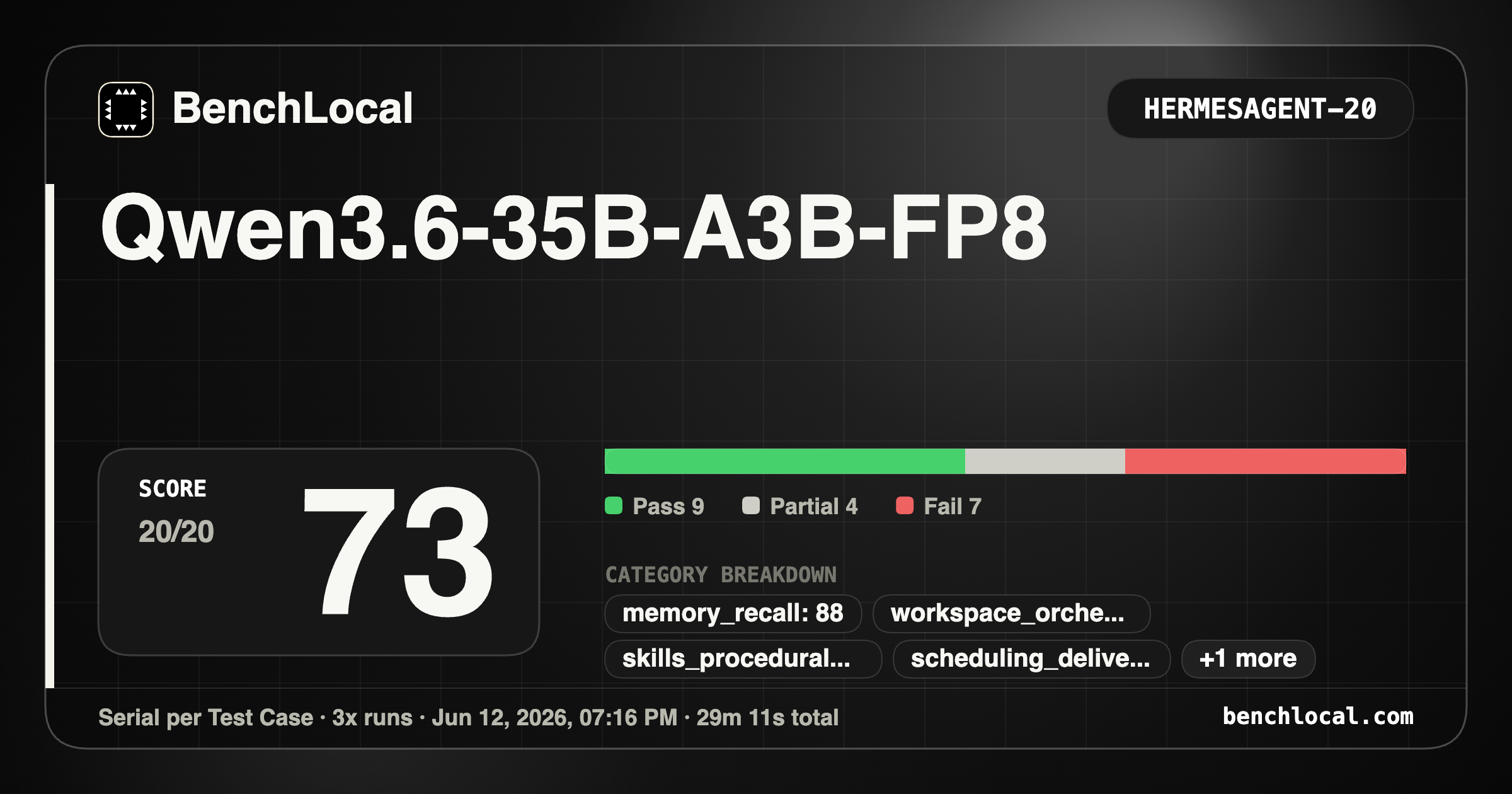
1. Qwen/Qwen3.6-35B-A3B-FP8
| BenchLocal.app Results |
Performance & Voicebot Metrics |
| Score: 86.6 |
PP: 958 t/s |
| ToolCall: 100 |
TTFT (warm): 64ms |
| InstrucFollow: 90 |
TG: 194.1 t/s |
| DataExtract: 86 |
Voicebot: 80% (279ms) |
| BugFind: 84 |
|
| HermesAgent: 73 |
Metrics: 5/6, 7/7, 5/9, 3/4, 4/4, 4/4, 1/3, 4/4 |
2. nvidia/Qwen3.6-35B-A3B-NVFP4
| BenchLocal.app Results |
Performance & Voicebot Metrics |
| Score: 84.4 |
PP: 1354 t/s |
| ToolCall: 97 |
TTFT (warm): 67ms |
| InstrucFollow: 98 |
TG: 230.6 t/s |
| DataExtract: 85 |
Voicebot: 82% (211ms) |
| BugFind: 84 |
|
| HermesAgent: 58 |
Metrics: 5/6, 7/7, 6/9, 2/4, 4/4, 4/4, 2/3, 4/4 |
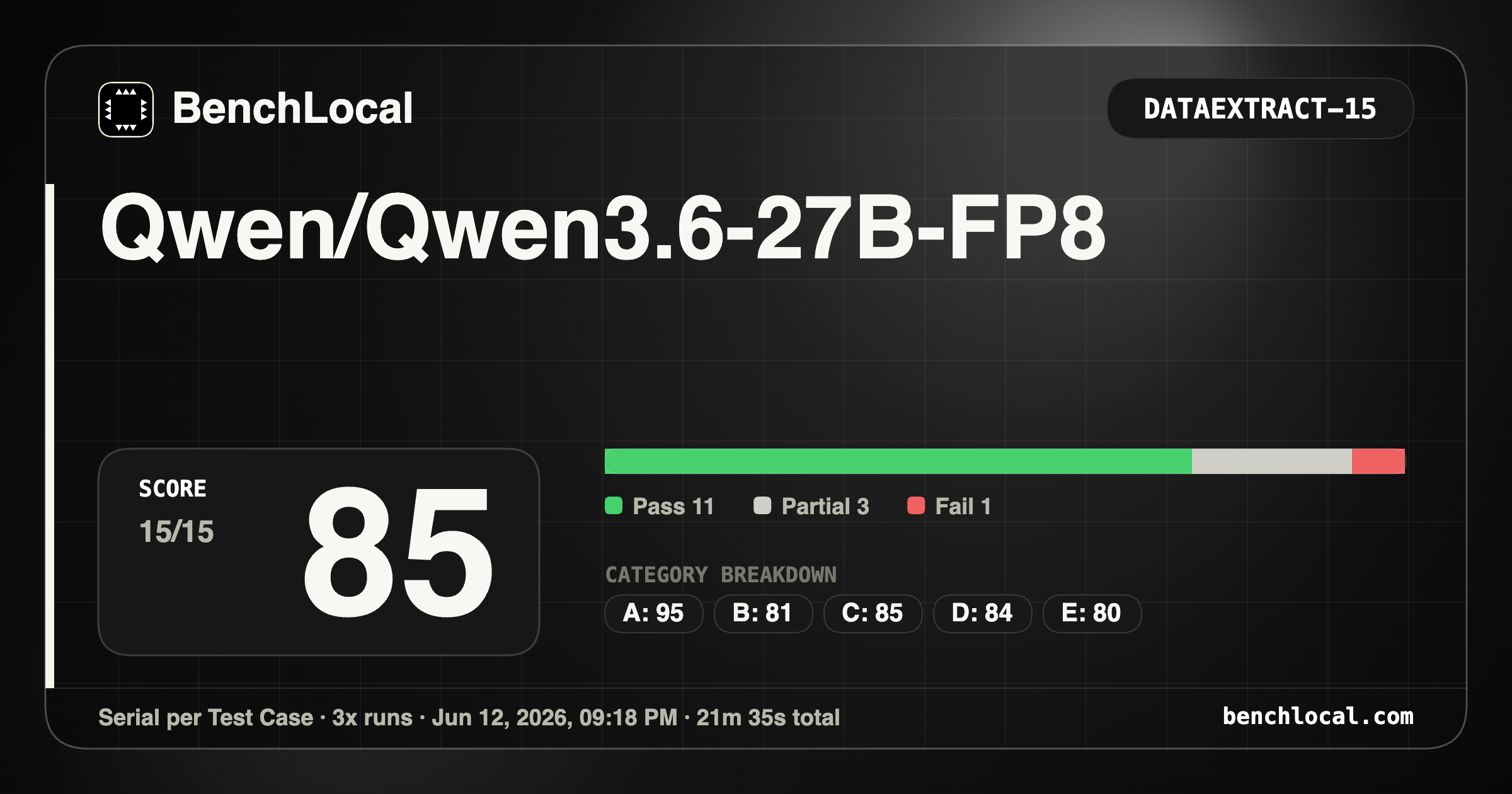
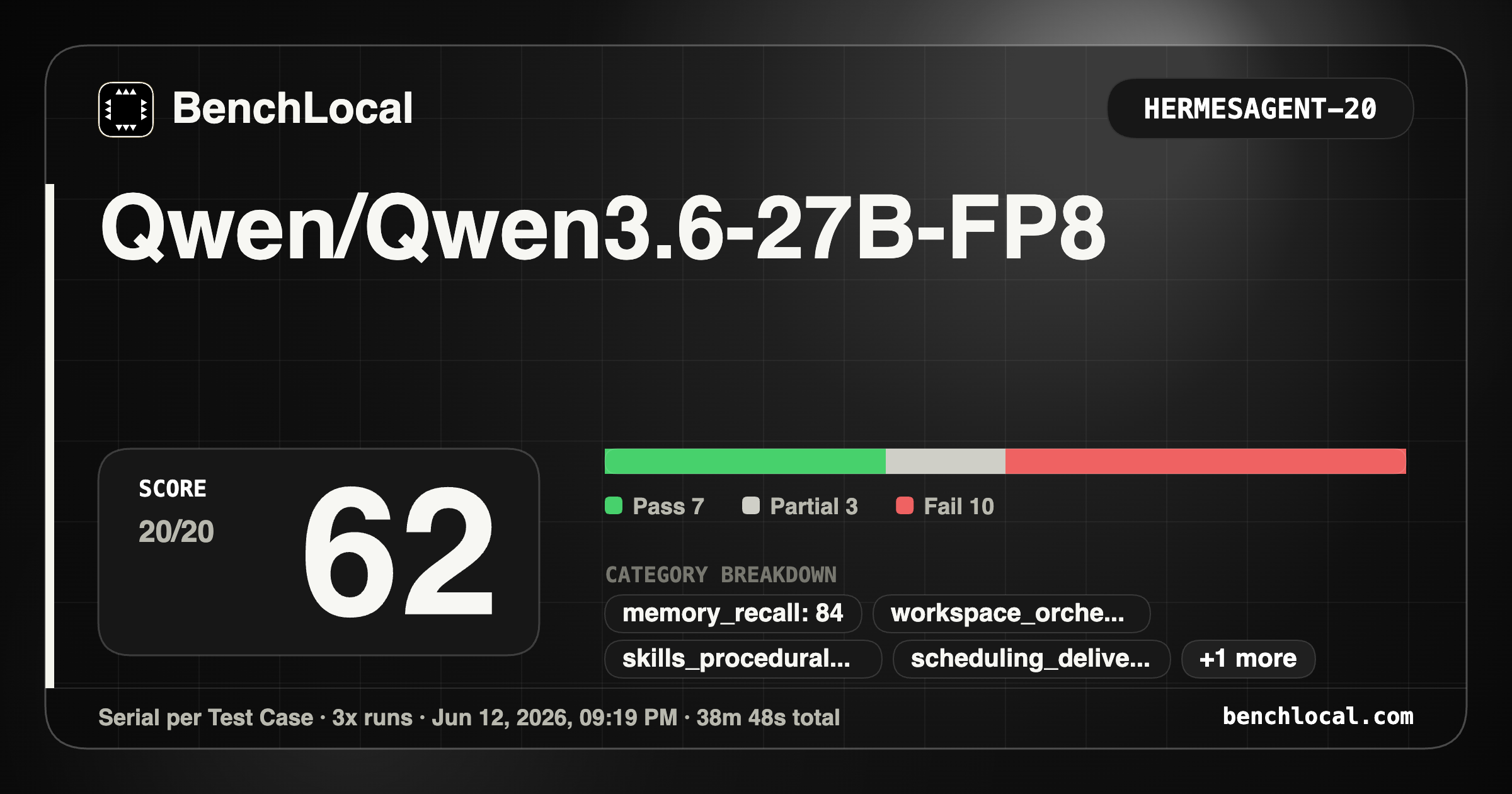
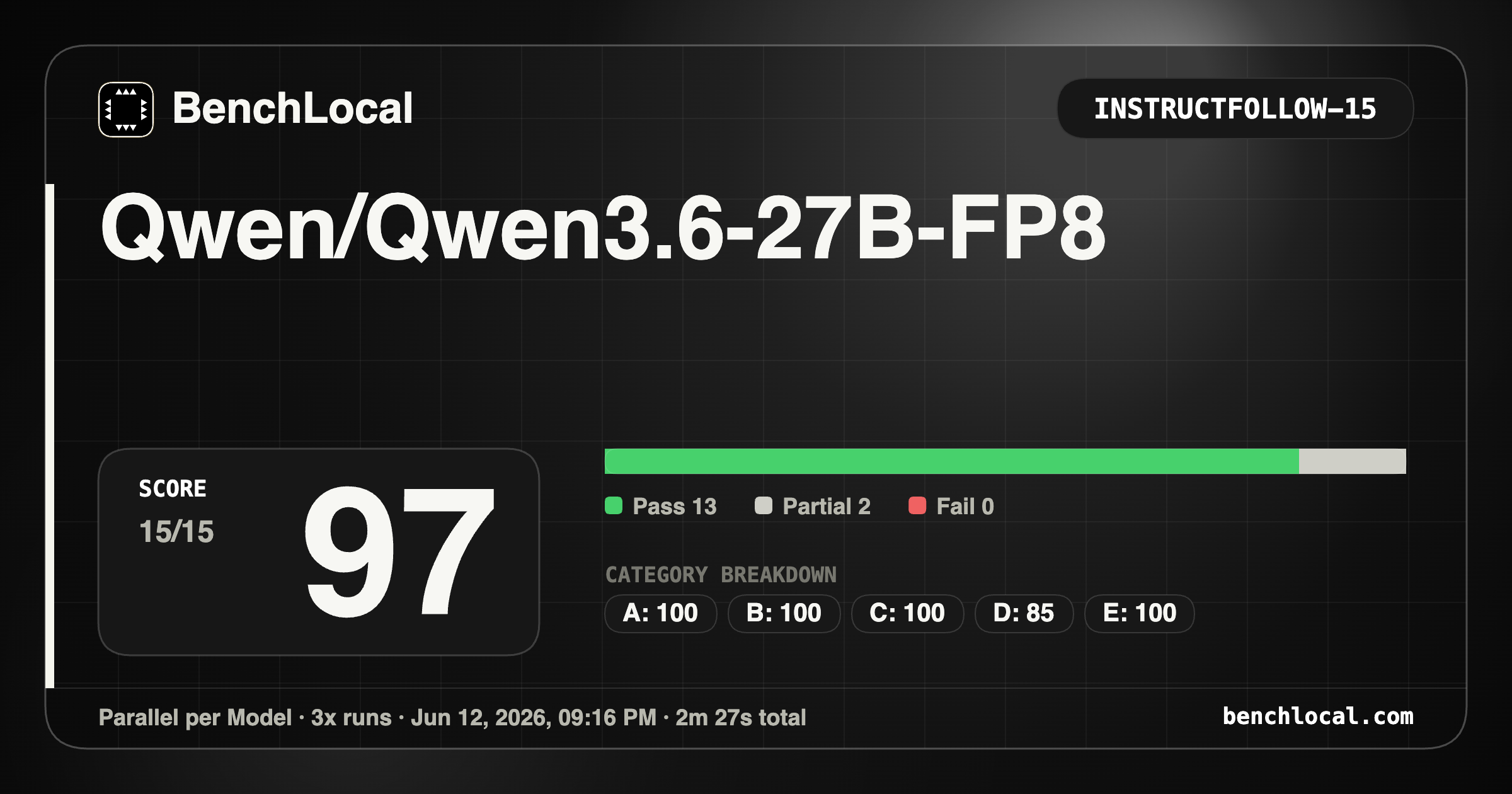
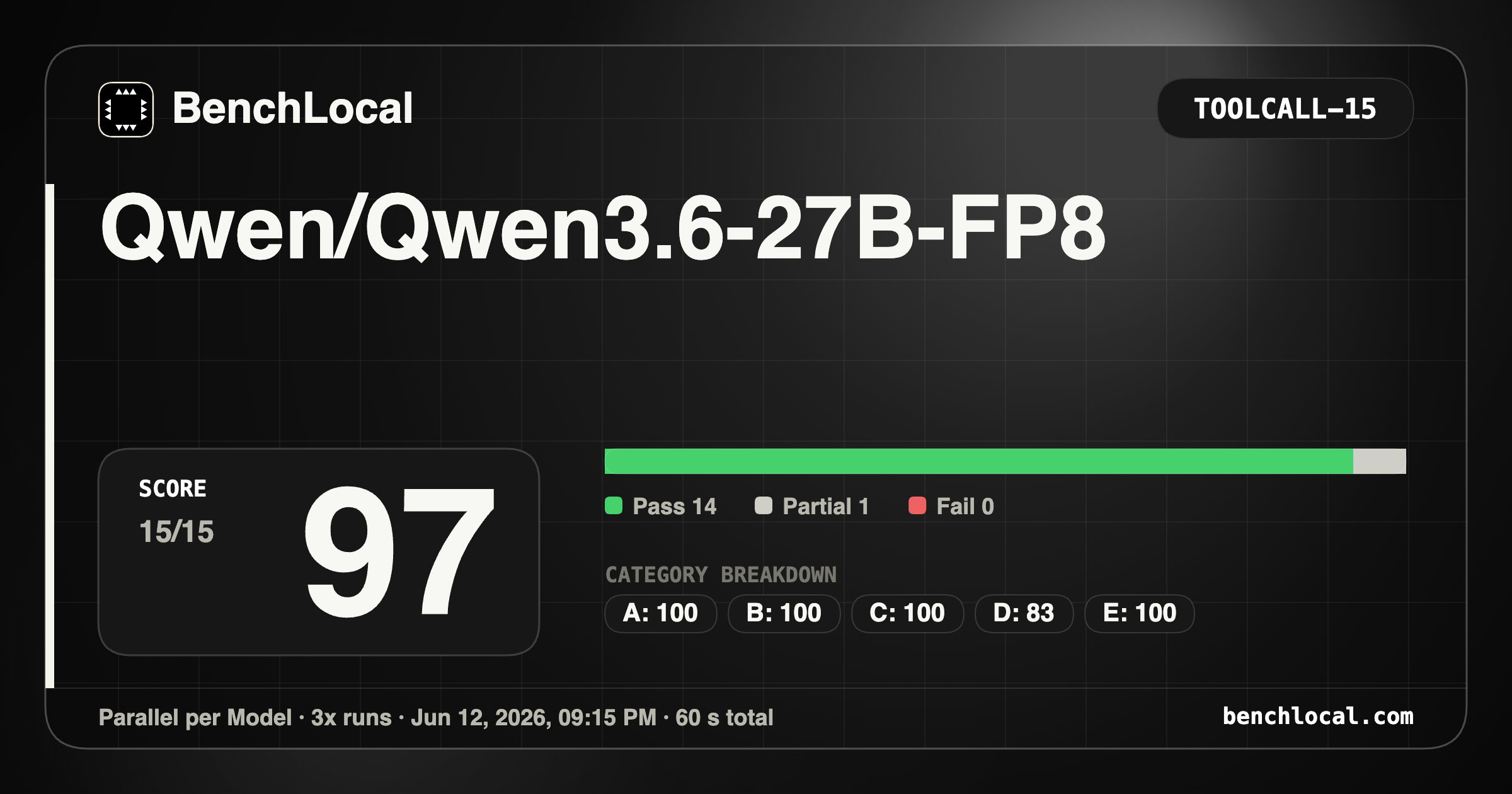
3. Qwen/Qwen3.6-27B-FP8
| BenchLocal.app Results |
Performance & Voicebot Metrics |
| Score: 86.2 |
PP: 3847 t/s |
| ToolCall: 97 |
TTFT (warm): 222ms |
| InstrucFollow: 97 |
TG: 82.0 t/s |
| DataExtract: 85 |
Voicebot: 85% (729ms) |
| BugFind: 90 |
|
| HermesAgent: 62 |
Metrics: 6/6, 7/7, 8/9, 3/4, 4/4, 2/4, 2/3, 3/4 |
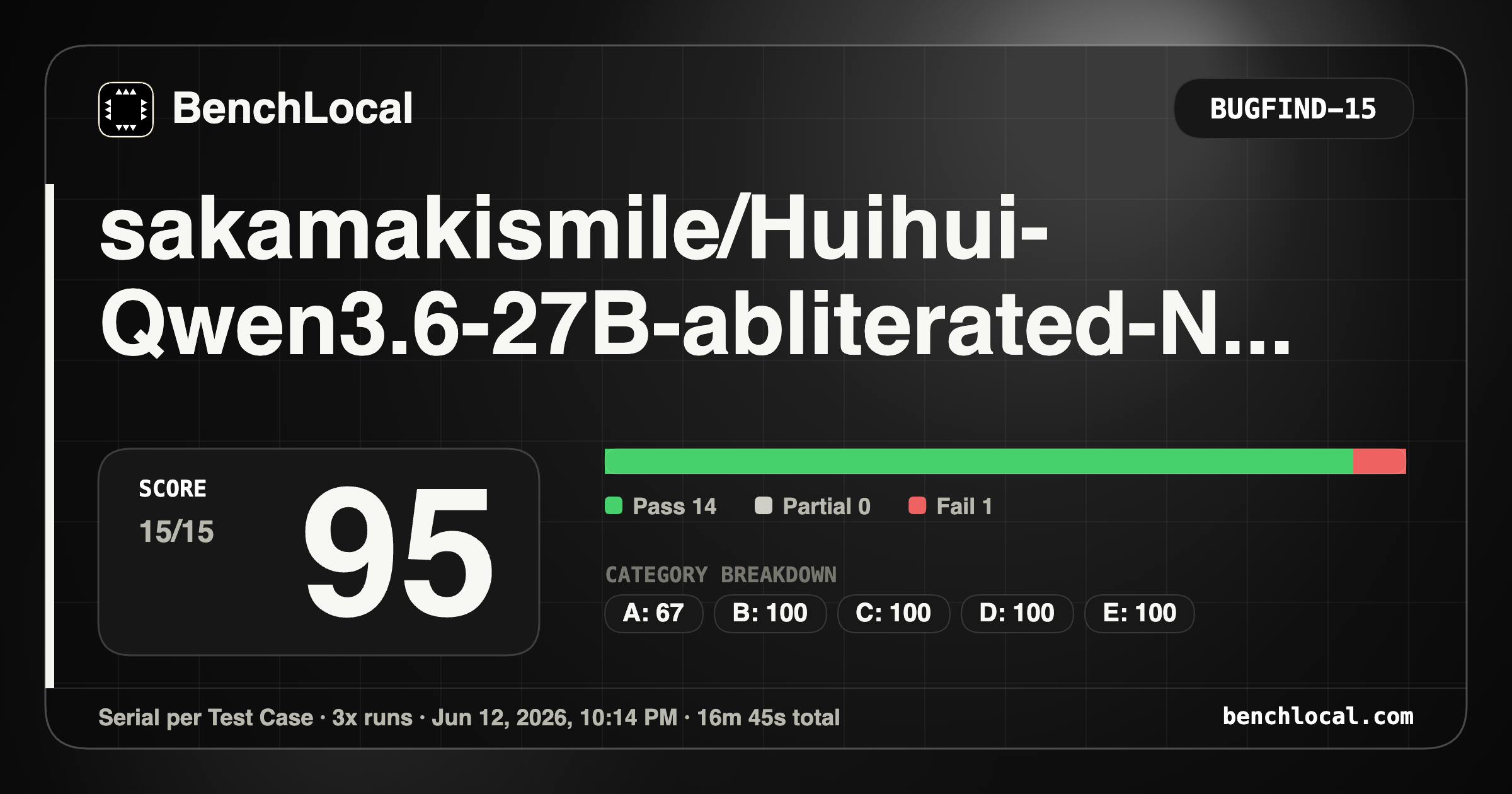
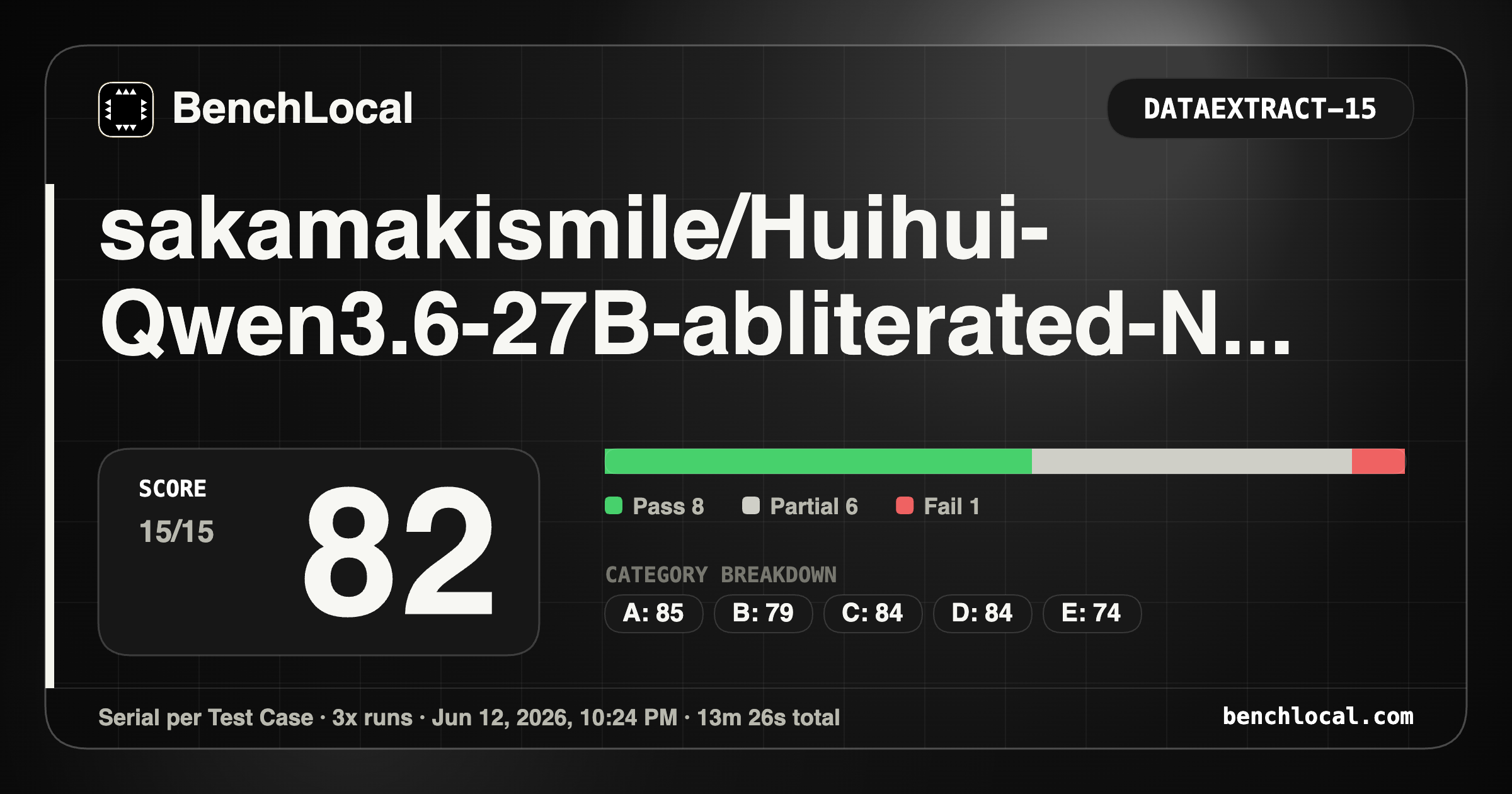
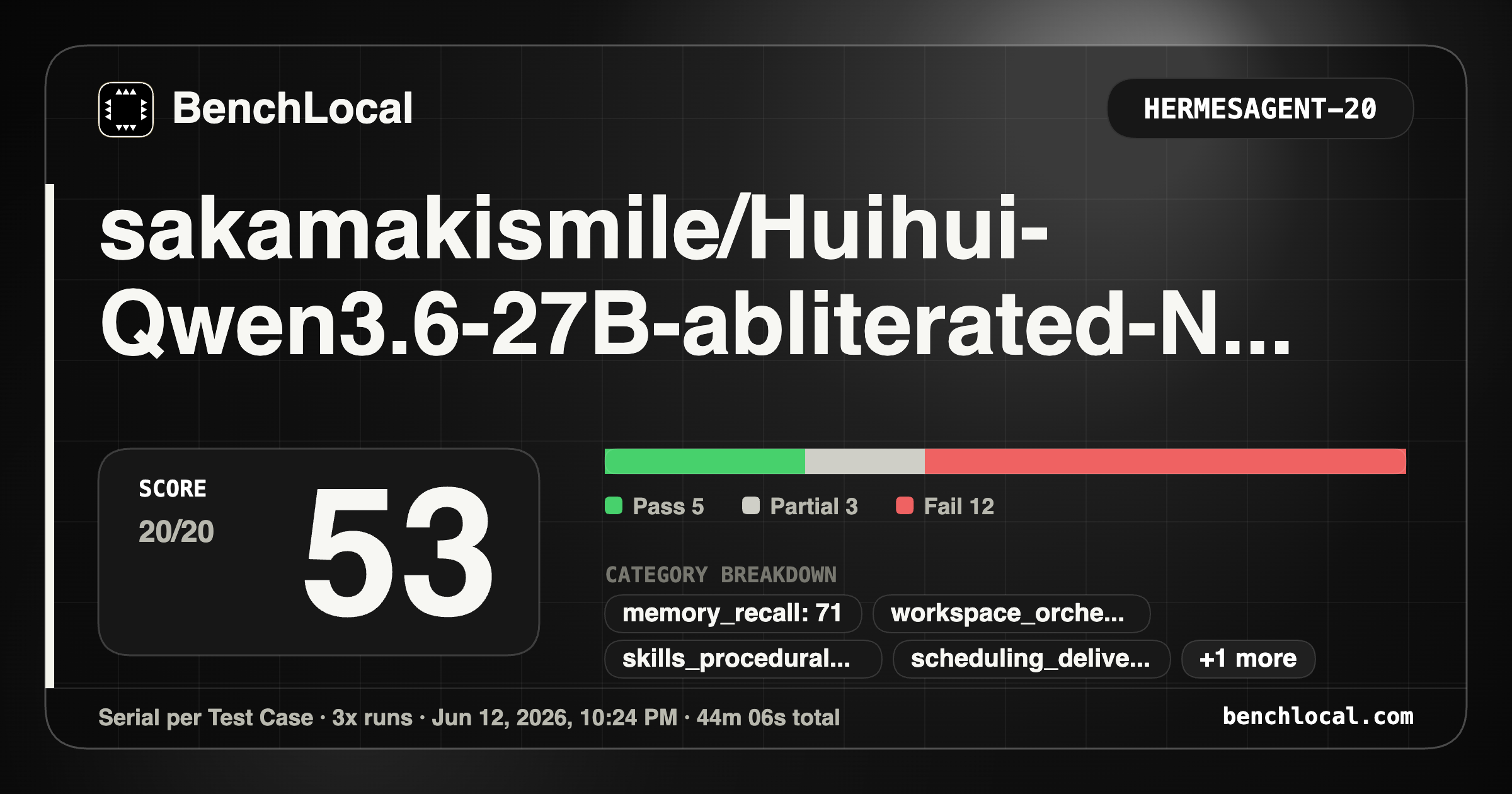
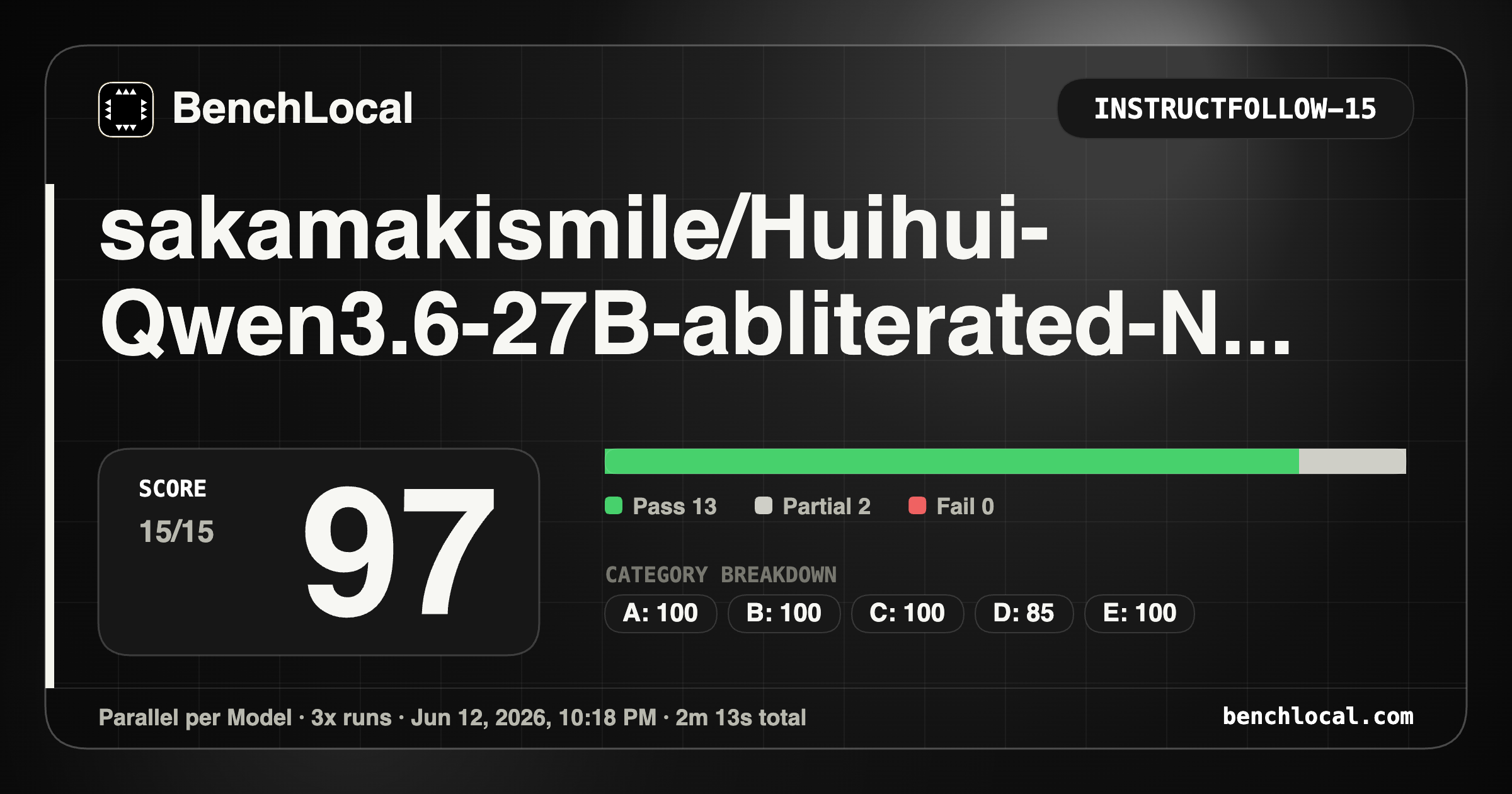
4. sakamakismile/Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP
| BenchLocal.app Results |
Performance & Voicebot Metrics |
| Score: 83.4 |
PP: 5465 t/s |
| ToolCall: 90 |
TTFT (warm): 153ms |
| InstrucFollow: 97 |
TG: 105 t/s |
| DataExtract: 82 |
Voicebot: 78% (679ms) |
| BugFind: 95 |
|
| HermesAgent: 53 |
Metrics: 5/6, 7/7, 7/9, 3/4, 3/4, 2/4, 1/3, 4/4 |
vLLM Deployment Recipe
To launch the Qwen/Qwen3.6-35B-A3B-FP8 variant on Blackwell hardware, use the following Docker Compose configuration. Note the flashinfer attention backend required for FP8 KV cache support.
Other models require different recipies.
services:
vllm:
image: "vllm/vllm-openai:nightly"
runtime: nvidia
restart: unless-stopped
ipc: host
shm_size: "32G"
environment:
- VLLM_LOGGING_LEVEL=info
- VLLM_HOST_IP=0.0.0.0
- HF_HOME=/root/.cache/huggingface
- HF_TOKEN=hf_Il....KbaA
- FLASHINFER_DISABLE_VERSION_CHECK=1
- FLASHINFER_CUDA_ARCH_LIST=12.0f
- VLLM_MOE_FORCE_MARLIN=1
- CUTE_DSL_ARCH=sm_120a
- PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
- VLLM_ALLOW_LONG_MAX_MODEL_LEN=1
- TRANSFORMERS_VERBOSITY=warning
volumes:
- ./llama-server/huggingface:/root/.cache/huggingface
- ./llama-server/vllm_cache:/root/.cache/vllm
ports:
- "8000:8000"
command: >
Qwen/Qwen3.6-35B-A3B-FP8
--served-model-name Qwen3.6-35B-A3B-FP8
--trust-remote-code
--host 0.0.0.0
--port 8000
--tensor-parallel-size 1
--dtype auto
--kv-cache-dtype fp8_e4m3
--attention-backend flashinfer
--moe-backend marlin
--gpu-memory-utilization 0.96
--max-model-len 262144
--max-num-seqs 32
--max-num-batched-tokens 65536
--enable-chunked-prefill
--enable-prefix-caching
--async-scheduling
--reasoning-parser qwen3
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--structured-outputs-config.backend xgrammar
--default-chat-template-kwargs '{"enable_thinking": true, "preserve_thinking": true}'
--speculative-config '{"method":"mtp","num_speculative_tokens":2,"moe_backend":"triton"}'
--override-generation-config '{"temperature":0.6,"top_p":0.95,"presence_penalty":0.05,"repetition_penalty":1.05}'
--language-model-only
-O3
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 30s
timeout: 10s
retries: 5
start_period: 120s
logging:
driver: "json-file"
options:
max-size: "20m"
max-file: "5"