Machine Learning for Titanic dissaster - Kaggle competition
Titanic: Machine Learning from Disaster
This is a second try to complete this Kaggle competition
- In this file use only SVM because was the best predictor in the previous sample.
- In this file the test data will be cured more carefully looking at the historigrams.
This Jupyter Notebook is an example of how to apply Machine Learning to the Titanic disaster
The sinking of the RMS Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. This sensational tragedy shocked the international community and led to better safety regulations for ships.
One of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.
Machine Learning
In this notebook we try to practice all the classification algorithms that we learned in this course.
We load a dataset using Pandas library, and apply the following algorithms, and find the best one for this specific dataset by accuracy evaluation methods.
Lets first load required libraries:
import itertools
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.ticker import NullFormatter
import pandas as pd
import numpy as np
import matplotlib.ticker as ticker
from sklearn import preprocessing
%matplotlib inline
# notice: installing seaborn might takes a few minutes
!conda install -c anaconda seaborn -y
About dataset
This dataset is about Titanic passengers. The train.csv data set includes details of 891 passengers of the first travel of the Titanic:
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
Lets download the datasets
# Submission file
!wget -O gender_submission.csv "https://storage.googleapis.com/kaggle-competitions-data/kaggle/3136/gender_submission.csv?GoogleAccessId=web-data@kaggle-161607.iam.gserviceaccount.com&Expires=1553770449&Signature=npMum5eXLm0%2B95BewgF6SVHrcaamF8F1tx57ycYmUVG9ILJ9Cmr6KD9zMWlmrWkDGh%2BQSZnhb5pVHqb9wJ65B%2BaRdzCeiJiFwA6FGhq%2B4RBpw6tmc3AZqic8DCPNhmLgWw55zjT1t2fHywhbxaiypF5hA6IOQqhxDCoOgXwqtIRNV7nZj5HRXlN%2BqR8UGL%2BO%2Fpi7QYoHuGIP2ZNQCgTMSon6rQNwnhYoMAi9KVIOOHYycimx2vX6zYEP3n9VA%2FAxMysr2sFhz%2FxJWi9%2FPd3X1LJe8RqvfjajPwUhVxiLi4uT7JzxpbXDHrRfJAD3dnnvGgHIskkW5jAuMuE%2BplNNmA%3D%3D"
--2019-03-25 11:56:06-- https://storage.googleapis.com/kaggle-competitions-data/kaggle/3136/gender_submission.csv?GoogleAccessId=web-data@kaggle-161607.iam.gserviceaccount.com&Expires=1553770449&Signature=npMum5eXLm0%2B95BewgF6SVHrcaamF8F1tx57ycYmUVG9ILJ9Cmr6KD9zMWlmrWkDGh%2BQSZnhb5pVHqb9wJ65B%2BaRdzCeiJiFwA6FGhq%2B4RBpw6tmc3AZqic8DCPNhmLgWw55zjT1t2fHywhbxaiypF5hA6IOQqhxDCoOgXwqtIRNV7nZj5HRXlN%2BqR8UGL%2BO%2Fpi7QYoHuGIP2ZNQCgTMSon6rQNwnhYoMAi9KVIOOHYycimx2vX6zYEP3n9VA%2FAxMysr2sFhz%2FxJWi9%2FPd3X1LJe8RqvfjajPwUhVxiLi4uT7JzxpbXDHrRfJAD3dnnvGgHIskkW5jAuMuE%2BplNNmA%3D%3D
Resolving storage.googleapis.com (storage.googleapis.com)... 216.58.211.240
Connecting to storage.googleapis.com (storage.googleapis.com)|216.58.211.240|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3258 (3.2K) [text/csv]
Saving to: 'gender_submission.csv'
gender_submission.c 100%[===================>] 3.18K --.-KB/s in 0s
2019-03-25 11:56:06 (8.90 MB/s) - 'gender_submission.csv' saved [3258/3258]
# test data file
!wget -O test.csv "https://storage.googleapis.com/kaggle-competitions-data/kaggle/3136/test.csv?GoogleAccessId=web-data@kaggle-161607.iam.gserviceaccount.com&Expires=1553770470&Signature=JroVG4v2wFgxCDlvpwoUTVWPP15WV5GUZ5oNImWiK7nUmcd2WO09DSaipZ4eUml5jKDuK1Qi1LjAAZWLalsKLHNRWQ6pULjFFAYozfb1CS7d7LLEXb7%2FCzqPhOapvgNV28eF9Jsl%2BkuTEXQYLf0xxigmMZh9NzUL3v1opX7FbxXQgpmy2F0Ci1NxNlKk7WGnioO45T4LnWoVhyYW5vNTVPYQa3KkQR6dc63w3jrxx6mzvSSczTLLnHj2luY9qbq%2BFMObKcaqfBzzq0l3uQCGGiMrLK5AlbCNiOVqBJveRmNk5rJ1bse4sV0giC3Fz0r7vInOfSiPr3qNyQZ1IDoOjg%3D%3D"
--2019-03-25 11:56:12-- https://storage.googleapis.com/kaggle-competitions-data/kaggle/3136/test.csv?GoogleAccessId=web-data@kaggle-161607.iam.gserviceaccount.com&Expires=1553770470&Signature=JroVG4v2wFgxCDlvpwoUTVWPP15WV5GUZ5oNImWiK7nUmcd2WO09DSaipZ4eUml5jKDuK1Qi1LjAAZWLalsKLHNRWQ6pULjFFAYozfb1CS7d7LLEXb7%2FCzqPhOapvgNV28eF9Jsl%2BkuTEXQYLf0xxigmMZh9NzUL3v1opX7FbxXQgpmy2F0Ci1NxNlKk7WGnioO45T4LnWoVhyYW5vNTVPYQa3KkQR6dc63w3jrxx6mzvSSczTLLnHj2luY9qbq%2BFMObKcaqfBzzq0l3uQCGGiMrLK5AlbCNiOVqBJveRmNk5rJ1bse4sV0giC3Fz0r7vInOfSiPr3qNyQZ1IDoOjg%3D%3D
Resolving storage.googleapis.com (storage.googleapis.com)... 216.58.211.240
Connecting to storage.googleapis.com (storage.googleapis.com)|216.58.211.240|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 28629 (28K) [text/csv]
Saving to: 'test.csv'
test.csv 100%[===================>] 27.96K --.-KB/s in 0.02s
2019-03-25 11:56:12 (1.42 MB/s) - 'test.csv' saved [28629/28629]
# train data file
!wget -O train.csv "https://storage.googleapis.com/kaggle-competitions-data/kaggle/3136/train.csv?GoogleAccessId=web-data@kaggle-161607.iam.gserviceaccount.com&Expires=1553770471&Signature=ImoWIFoTzTBcmNL9o8BRgQ3s13MMBveBDw6W7MTGjq0KNMTDqNYKmVAsBOHaSdvcUMHbtWY5CV7DwsNb5SzjbioSUvCZRaIANXS%2FMkH2MDkcFrgCwb0wXZ5rp9nRfonlYga%2FwjcqikCcQFhuwtTp9QkLbU4r8Gs0vQ3YF8WoGFEIESkmNY9k1n1sLfVuuxfdvYZ69Spox1q5UMSDq6kTETPz3In4spF1B0nj%2BwX6MVgotl6zF%2BoHpLMX3Hfu46rhOKW3JJddWYoCmFTdVjAd0w%2FEEeZ%2FQ4%2FuH7zaRQyay1UwSMr0JVyZXIlc7mZSpA4s%2B%2BSngeiQhzDiPN1FoF1YQA%3D%3D"
--2019-03-25 11:56:18-- https://storage.googleapis.com/kaggle-competitions-data/kaggle/3136/train.csv?GoogleAccessId=web-data@kaggle-161607.iam.gserviceaccount.com&Expires=1553770471&Signature=ImoWIFoTzTBcmNL9o8BRgQ3s13MMBveBDw6W7MTGjq0KNMTDqNYKmVAsBOHaSdvcUMHbtWY5CV7DwsNb5SzjbioSUvCZRaIANXS%2FMkH2MDkcFrgCwb0wXZ5rp9nRfonlYga%2FwjcqikCcQFhuwtTp9QkLbU4r8Gs0vQ3YF8WoGFEIESkmNY9k1n1sLfVuuxfdvYZ69Spox1q5UMSDq6kTETPz3In4spF1B0nj%2BwX6MVgotl6zF%2BoHpLMX3Hfu46rhOKW3JJddWYoCmFTdVjAd0w%2FEEeZ%2FQ4%2FuH7zaRQyay1UwSMr0JVyZXIlc7mZSpA4s%2B%2BSngeiQhzDiPN1FoF1YQA%3D%3D
Resolving storage.googleapis.com (storage.googleapis.com)... 216.58.211.240
Connecting to storage.googleapis.com (storage.googleapis.com)|216.58.211.240|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 61194 (60K) [text/csv]
Saving to: 'train.csv'
train.csv 100%[===================>] 59.76K --.-KB/s in 0.04s
2019-03-25 11:56:18 (1.62 MB/s) - 'train.csv' saved [61194/61194]
Load Data From CSV File
df = pd.read_csv('train.csv')
df = df.set_index(['PassengerId'])
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
df.shape
(891, 11)
Clean data
Convert ‘Sex’ feature into categorical values (dummies)
df = pd.concat([df,pd.get_dummies(df['Sex'])], axis=1)
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | female | male | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 | 0 |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 | 0 |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1 | 0 |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 1 |
Convert ‘Embarked’ feature into categorical values (dummies)
df = pd.concat([df,pd.get_dummies(df['Embarked'])], axis=1)
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | female | male | C | Q | S | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | ||||||||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 | 0 | 0 | 1 |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 | 0 | 1 | 0 | 0 |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 | 0 | 0 | 0 | 1 |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1 | 0 | 0 | 0 | 1 |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 1 | 0 | 0 | 1 |
Create a title column to manage title names
title = [item.split(', ')[1].split('.')[0] for item in df['Name']]
df['Title'] = pd.Series(title)
df['Title'] = df['Title'].replace(['Don', 'Rev', 'Dr', 'Mme', 'Ms', 'Major', 'Lady', 'Sir',
'Mlle', 'Col', 'the Countess', 'Jonkheer'], 'Rare')
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | female | male | C | Q | S | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 | 0 | 0 | 1 | Mrs |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 | 0 | 1 | 0 | 0 | Miss |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 | 0 | 0 | 0 | 1 | Mrs |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1 | 0 | 0 | 0 | 1 | Mr |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 1 | 0 | 0 | 1 | Mr |
Convert class into categorical fields
df = pd.concat([df,pd.get_dummies(df['Pclass'])], axis=1)
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | female | male | C | Q | S | Title | 1 | 2 | 3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | ||||||||||||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 | 0 | 0 | 1 | Mrs | 0 | 0 | 1 |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 | 0 | 1 | 0 | 0 | Miss | 1 | 0 | 0 |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 | 0 | 0 | 0 | 1 | Mrs | 0 | 0 | 1 |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1 | 0 | 0 | 0 | 1 | Mr | 1 | 0 | 0 |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 1 | 0 | 0 | 1 | Mr | 0 | 0 | 1 |
Convert title into categorical fields
df = pd.concat([df,pd.get_dummies(df['Title'])], axis=1)
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | ... | Title | 1 | 2 | 3 | Capt | Master | Miss | Mr | Mrs | Rare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | ... | Mrs | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | ... | Miss | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | ... | Mrs | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | ... | Mr | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | ... | Mr | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
5 rows × 26 columns
Data visualization and pre-processing
Correlation matrix
corr = df.corr()
corr.style.background_gradient(cmap='coolwarm').set_precision(2)
| Survived | Pclass | Age | SibSp | Parch | Fare | female | male | C | Q | S | 1 | 2 | 3 | Capt | Master | Miss | Mr | Mrs | Rare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Survived | 1 | -0.34 | -0.077 | -0.035 | 0.082 | 0.26 | 0.54 | -0.54 | 0.17 | 0.0037 | -0.16 | 0.29 | 0.093 | -0.32 | 0.042 | -0.0039 | -0.016 | 0.0091 | 0.02 | -0.027 |
| Pclass | -0.34 | 1 | -0.37 | 0.083 | 0.018 | -0.55 | -0.13 | 0.13 | -0.24 | 0.22 | 0.082 | -0.89 | -0.19 | 0.92 | 0.028 | 0.011 | -0.061 | 0.04 | -0.0061 | 0.016 |
| Age | -0.077 | -0.37 | 1 | -0.31 | -0.19 | 0.096 | -0.093 | 0.093 | 0.036 | -0.022 | -0.033 | 0.35 | 0.007 | -0.31 | 0.0034 | -0.035 | -0.03 | -0.014 | 0.04 | 0.067 |
| SibSp | -0.035 | 0.083 | -0.31 | 1 | 0.41 | 0.16 | 0.11 | -0.11 | -0.06 | -0.026 | 0.071 | -0.055 | -0.056 | 0.093 | -0.016 | 0.02 | -0.031 | 0.052 | -0.027 | -0.04 |
| Parch | 0.082 | 0.018 | -0.19 | 0.41 | 1 | 0.22 | 0.25 | -0.25 | -0.011 | -0.081 | 0.063 | -0.018 | -0.00073 | 0.016 | -0.016 | 0.012 | -0.043 | 0.048 | -0.039 | 0.034 |
| Fare | 0.26 | -0.55 | 0.096 | 0.16 | 0.22 | 1 | 0.18 | -0.18 | 0.27 | -0.12 | -0.17 | 0.59 | -0.12 | -0.41 | -0.016 | -0.0019 | 0.041 | -0.022 | 0.0039 | -0.033 |
| female | 0.54 | -0.13 | -0.093 | 0.11 | 0.25 | 0.18 | 1 | -1 | 0.083 | 0.074 | -0.13 | 0.098 | 0.065 | -0.14 | -0.025 | -0.0011 | -0.042 | 0.039 | 0.02 | -0.044 |
| male | -0.54 | 0.13 | 0.093 | -0.11 | -0.25 | -0.18 | -1 | 1 | -0.083 | -0.074 | 0.13 | -0.098 | -0.065 | 0.14 | 0.025 | 0.0011 | 0.042 | -0.039 | -0.02 | 0.044 |
| C | 0.17 | -0.24 | 0.036 | -0.06 | -0.011 | 0.27 | 0.083 | -0.083 | 1 | -0.15 | -0.78 | 0.3 | -0.13 | -0.15 | -0.016 | -0.049 | 0.062 | -0.042 | 0.0036 | 0.036 |
| Q | 0.0037 | 0.22 | -0.022 | -0.026 | -0.081 | -0.12 | 0.074 | -0.074 | -0.15 | 1 | -0.5 | -0.16 | -0.13 | 0.24 | -0.01 | -0.028 | 0.023 | 0.036 | -0.067 | -0.0059 |
| S | -0.16 | 0.082 | -0.033 | 0.071 | 0.063 | -0.17 | -0.13 | 0.13 | -0.78 | -0.5 | 1 | -0.17 | 0.19 | -0.0095 | 0.021 | 0.062 | -0.066 | 0.015 | 0.034 | -0.027 |
| 1 | 0.29 | -0.89 | 0.35 | -0.055 | -0.018 | 0.59 | 0.098 | -0.098 | 0.3 | -0.16 | -0.17 | 1 | -0.29 | -0.63 | -0.019 | -0.0088 | 0.051 | -0.043 | 0.02 | -0.02 |
| 2 | 0.093 | -0.19 | 0.007 | -0.056 | -0.00073 | -0.12 | 0.065 | -0.065 | -0.13 | -0.13 | 0.19 | -0.29 | 1 | -0.57 | -0.017 | -0.0035 | 0.017 | 0.0081 | -0.03 | 0.01 |
| 3 | -0.32 | 0.92 | -0.31 | 0.093 | 0.016 | -0.41 | -0.14 | 0.14 | -0.15 | 0.24 | -0.0095 | -0.63 | -0.57 | 1 | 0.03 | 0.01 | -0.058 | 0.03 | 0.0073 | 0.009 |
| Capt | 0.042 | 0.028 | 0.0034 | -0.016 | -0.016 | -0.016 | -0.025 | 0.025 | -0.016 | -0.01 | 0.021 | -0.019 | -0.017 | 0.03 | 1 | -0.0073 | -0.017 | -0.039 | -0.014 | -0.0058 |
| Master | -0.0039 | 0.011 | -0.035 | 0.02 | 0.012 | -0.0019 | -0.0011 | 0.0011 | -0.049 | -0.028 | 0.062 | -0.0088 | -0.0035 | 0.01 | -0.0073 | 1 | -0.11 | -0.25 | -0.088 | -0.038 |
| Miss | -0.016 | -0.061 | -0.03 | -0.031 | -0.043 | 0.041 | -0.042 | 0.042 | 0.062 | 0.023 | -0.066 | 0.051 | 0.017 | -0.058 | -0.017 | -0.11 | 1 | -0.59 | -0.2 | -0.088 |
| Mr | 0.0091 | 0.04 | -0.014 | 0.052 | 0.048 | -0.022 | 0.039 | -0.039 | -0.042 | 0.036 | 0.015 | -0.043 | 0.0081 | 0.03 | -0.039 | -0.25 | -0.59 | 1 | -0.47 | -0.2 |
| Mrs | 0.02 | -0.0061 | 0.04 | -0.027 | -0.039 | 0.0039 | 0.02 | -0.02 | 0.0036 | -0.067 | 0.034 | 0.02 | -0.03 | 0.0073 | -0.014 | -0.088 | -0.2 | -0.47 | 1 | -0.07 |
| Rare | -0.027 | 0.016 | 0.067 | -0.04 | 0.034 | -0.033 | -0.044 | 0.044 | 0.036 | -0.0059 | -0.027 | -0.02 | 0.01 | 0.009 | -0.0058 | -0.038 | -0.088 | -0.2 | -0.07 | 1 |
The mayor correlation with ‘Survived’ is the ‘female’ feature. Woman had more probability to survive the disaster. Also we can see that there were more female than male who travel with siblins
Lets plot some columns to underestand data better:
import seaborn as sns
bins = np.linspace(df.Age.min(), df.Age.max(), 10)
g = sns.FacetGrid(df, col="male", hue="Pclass", palette="Set1", col_wrap=2)
g.map(plt.hist, 'Age', bins=bins, ec="k")
g.axes[-1].legend()
plt.show()
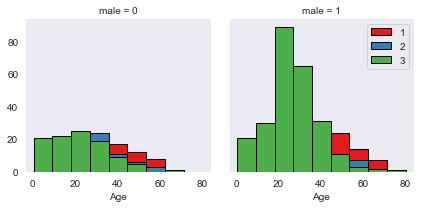
- First grid: Females per Age
- Second grid: Males per Age
- Red: First class
- Blue: Second class
- Green: Third class
bins = np.linspace(df.Age.min(), df.Age.max(), 10)
g = sns.FacetGrid(df, col="male", hue="Survived", palette="Set1", col_wrap=2)
g.map(plt.hist, 'Age', bins=bins, ec="k")
g.axes[-1].legend()
plt.show()
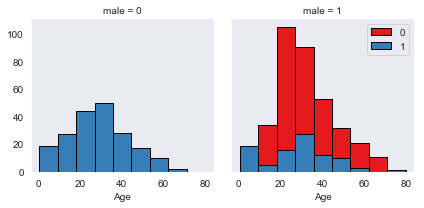
All woman survived. Child males also survived.
# Take only males to distinguish which classes survived the most
male_df = df[df.male != 0]
male_df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | ... | Title | 1 | 2 | 3 | Capt | Master | Miss | Mr | Mrs | Rare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | ... | Mrs | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | ... | Mr | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | ... | Mr | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | ... | Master | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | ... | Mrs | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
5 rows × 26 columns
bins = np.linspace(male_df.Age.min(), male_df.Age.max(), 10)
g = sns.FacetGrid(male_df, col="Pclass", hue="Survived", palette="Set1", col_wrap=2)
g.map(plt.hist, 'Age', bins=bins, ec="k")
g.axes[-1].legend()
plt.show()
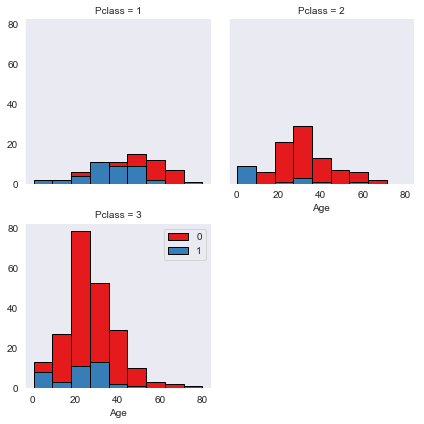
First class males had the most survival probability
Check number of survivors by sex
sns.countplot(data=df, x='Survived', hue='Sex')
<matplotlib.axes._subplots.AxesSubplot at 0x1a1a951048>
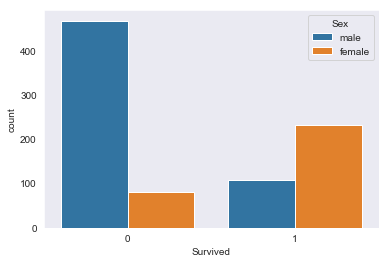
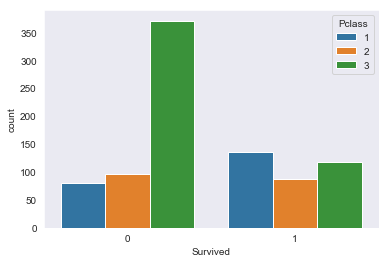
Survived by class
sns.countplot(data=df, x='Survived', hue='Pclass')
<matplotlib.axes._subplots.AxesSubplot at 0x1a1c1ec908>
Prepare data
Remove unneeded features
df.drop(['Name', 'Sex', 'Ticket', 'Fare', 'Embarked', 'Cabin', 'Pclass', 'Title'], axis=1, inplace=True)
df.head()
| Survived | Age | SibSp | Parch | female | male | C | Q | S | 1 | 2 | 3 | Capt | Master | Miss | Mr | Mrs | Rare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | ||||||||||||||||||
| 1 | 0 | 22.0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 1 | 38.0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 1 | 26.0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 35.0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 5 | 0 | 35.0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
# Drop NAN
df = df.dropna()
df.shape
(714, 18)
Feature = df.astype(np.float64)
X = Feature.drop(['Survived'], axis=1)
X.shape
(714, 17)
What are our lables?
y = df['Survived'].values
y[0:5]
array([0, 1, 1, 1, 0])
Normalize Data
Data Standardization give data zero mean and unit variance (technically should be done after train test split )
# X= preprocessing.StandardScaler().fit(X).transform(X)
X[0:5]
| Age | SibSp | Parch | female | male | C | Q | S | 1 | 2 | 3 | Capt | Master | Miss | Mr | Mrs | Rare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||||||
| 1 | 22.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 38.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 26.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 35.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 5 | 35.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
Classification
Use only:
- Support Vector Machine
Support Vector Machine
from sklearn import svm
model_svm = svm.SVC(kernel='linear')
model_svm.fit(X, y)
model_svm
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='linear', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
Let’s prepare a submission for the Kaggle competion
# Load test data
df_test = pd.read_csv('test.csv')
df_test.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
Cure data
Fill the Age using rules
Each rule will depend on the rest of the data:
- If the name of a woman starts with Mrs and have children, put an age between 25 and 40
- If a male travels alone, put the average age of the males traveling alone.
# Find women with children/parents with Mrs in his name
df_test2 = df_test[df_test['Name'].str.contains("Mrs", regex=False)]
avg = df_test2['Age'].mean()
df_test.loc[df_test['Name'].str.contains("Mrs", regex=False), 'Age'] = df_test.loc[df_test['Name'].str.contains("Mrs", regex=False), 'Age'].fillna(avg)
df_test.loc[df_test['Name'].str.contains("Ms.", regex=False), 'Age'] = df_test.loc[df_test['Name'].str.contains("Ms.", regex=False), 'Age'].fillna(avg)
df_test.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
# Find men traveling alone and put the average of all
df_test2 = df_test.loc[(df_test['Sex'] == 'male') & (df_test['Parch'] == 0) & (df_test['SibSp'] == 0)]
avg = df_test2['Age'].mean()
df_test.loc[(df_test['Sex'] == 'male') & (df_test['Parch'] == 0) & (df_test['SibSp'] == 0), 'Age'] = df_test.loc[(df_test['Sex'] == 'male') & (df_test['Parch'] == 0) & (df_test['SibSp'] == 0), 'Age'].fillna(avg)
df_test.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
# Fill with average of Miss each one nan
df_test2 = df_test[df_test['Name'].str.contains("Miss", regex=False)]
avg = df_test2['Age'].mean()
print(avg)
df_test.loc[df_test['Name'].str.contains("Miss", regex=False), 'Age'] = df_test.loc[df_test['Name'].str.contains("Miss", regex=False), 'Age'].fillna(avg)
df_test.head()
21.774843750000002
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
# The rest of males put the average of all males
df_test2 = df_test.loc[(df_test['Sex'] == 'male')]
avg = df_test2['Age'].mean()
df_test.loc[(df_test['Sex'] == 'male'), 'Age'] = df_test.loc[(df_test['Sex'] == 'male'), 'Age'].fillna(avg)
df_test.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
df_test[df_test.Age.isnull()]
# No more nan in Age
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|
Prepare test data the same way the train data
df_test = df_test.set_index(['PassengerId'])
df_test = pd.concat([df_test,pd.get_dummies(df_test['Sex'])], axis=1)
df_test = pd.concat([df_test,pd.get_dummies(df_test['Embarked'])], axis=1)
title = [item.split(', ')[1].split('.')[0] for item in df_test['Name']]
df_test['Title'] = pd.Series(title, index=df_test.index)
df_test['Title'] = df_test['Title'].replace(['Don', 'Rev', 'Dr', 'Mme', 'Ms', 'Major', 'Lady', 'Sir',
'Mlle', 'Col', 'the Countess', 'Jonkheer'], 'Rare')
df_test = pd.concat([df_test,pd.get_dummies(df_test['Pclass'])], axis=1)
df_test = pd.concat([df_test,pd.get_dummies(df_test['Title'])], axis=1)
df_test.drop(['Name', 'Sex', 'Fare', 'Ticket', 'Embarked', 'Cabin', 'Pclass', 'Title'], axis=1, inplace=True)
df_test2 = df_test.dropna()
df_test2.shape
(418, 17)
Feature = df_test.astype(np.float64)
X_test = Feature
X_test.shape
(418, 17)
# X_test = preprocessing.StandardScaler().fit(X_test).transform(X_test)
X_test[0:5]
| Age | SibSp | Parch | female | male | C | Q | S | 1 | 2 | 3 | Dona | Master | Miss | Mr | Mrs | Rare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||||||
| 892 | 34.5 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 893 | 47.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 894 | 62.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 895 | 27.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 896 | 22.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
yhat_test = model_svm.predict(X_test)
yhat_test[0:50]
array([0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0,
1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 1, 1])
from sklearn.linear_model import LogisticRegression
logmodel = LogisticRegression(solver='liblinear')
logmodel.fit(X, y)
yhat_test = logmodel.predict(X_test)
Prepare submission
submission_df = pd.read_csv('gender_submission.csv', index_col=False)
submission_df.head()
| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 1 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
results = pd.DataFrame(yhat_test)
def transformValueR(x):
if x > 0.5:
return 1
return 0
fixed_results = results[0].apply(lambda x: transformValueR(x))
t = pd.concat([submission_df['PassengerId'], fixed_results], axis=1, keys=['PassengerId', 'Survived'])
t = t.set_index('PassengerId')
t.to_csv("submission_cured_more_dummies.csv")
t.head()
| Survived | |
|---|---|
| PassengerId | |
| 892 | 0 |
| 893 | 0 |
| 894 | 0 |
| 895 | 0 |
| 896 | 1 |