La Arquitectura Limpia
Esto es una traducción al idioma español del artículo de Uncle Bob: The Clean Architecture
A lo largo de los últimos años hemos visto un amplio conjunto de ideas acerca de la arquitectura de los sistemas. Estos incluyen:
- Hexagonal Architecture (también conocido como Puertos y Adaptadores) por Alistair Cockburn y adoptado por Steve Freema y Nat Pryce en su fantástico libro Growing Object Oriented Software
- Onion Architecture por Jeffrey Palermo
- Screaming Arquitecture de mi blog del año pasado
- DCI de James Coplien y Trygve Reenskaug
- BCE por Ivar Jacobson de su libro Object Oriented Software Engineering: A Use-Case Driven Approach
Todas estas aquitecturas aunque varían en algunos de sus detalles, son muy similares. Todas ellas tienen el mismo objetivo, el cual es la separación de los asuntos. Todos ellos consiguen esta separación dividiendo el software en capas. Cada cual tiene al menos una capa para la reglas de negocio y otro para los interfaces.
Cada una de estas arquitecturas producen sistemas que son:
- Independientes de los Frameworks. La arquitectura no depende de la existencia de cierta librería llena de características. Esto te permite usar esos frameworks como herramientas, en vez de tener que atiborrar tu sistema de sus limitadas restricciones.
- Testeable, Las reglas de negocio pueden ser testeadas sin el IU, base de datos, servidor web, o cualquier otros elemento externo.
- Independientes de IU. El IU puede cambiar facilmente, sin cambier el resto del sistema. Un IU web podría ser reemplezado por un IU de consola, por ejemplo, sin cambiar las reglas de negocio.
- Independiente de la base de datos. Puedes cambiar Oracle o SQL Server por Mongo, BigTable, CouchDB, o cualquier otro. De hecho tus reglas de negocio no están atadas a la base de datos.
- Independiente de cualquier agencia externa. De hecho tus reglas de negocio simplemente no saben nada acerca del resto del mundo.
La Regla de Dependencia
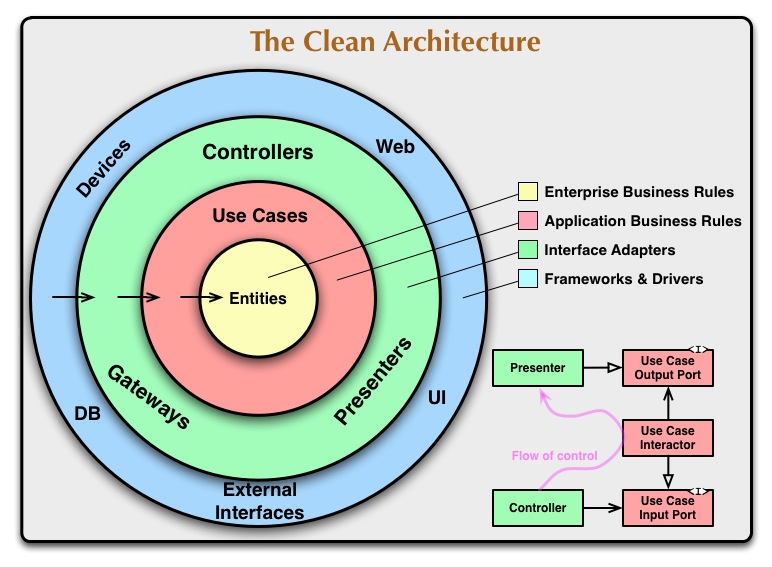
Los círculos concentricos representan diferentes areas del software. En general, cuanto más lejos llegas, mayor es el nivel del software. Lo círculos externos son mecanismos. Los círculos internos son políticas.
La norma principal que hace funcionar esta arquitectura es la Regla de Dependencia. Esta regla dice que las dependencias del código fuente solo pueden apuntar hacia adentro. Nada dentro de un círculo puede saber algo de un círculo externo. En particular, el nombre de algo declarado en un círculo externo no debe ser mencionado por el código en un círculo interno. Esto incluye, funciones, clases, variables o cualquier otro entidad de software con nombre.
Por el mismo motivo, los formatos de datos usados en un círculo exterior no deben ser usados en un círculo interior, especialmente si esos formatos son generados por un framework de un círculo externo. No queremos que nada de un círculo externo impacte en los círculos internos.
Entidades
Las entidades encapsulan las reglas de negocio de toda la empresa. Una entidad puede ser un objeto con métodos o puede ser un conjunto de datos y funciones. No importa mucho si las entidades podrían ser usadas en muchas aplicaciones diferentes de la empresa.
Si no tienes una empresa y solo escribes una aplicación unitaria, entonces estas entidades son los objetos de negocio de la aplicación. Encapsulan las más generales y principales reglas. Son lo que probablemente no cambie debido a cambios externos. Por ejemplo: no puedes esperar que estos objetos cambien por un cambio en el método de paginación o la seguridad. Ningún cambio operacional a una aplicación debería afectar a la capa de entidad.
Casos de Uso
El software en esta capa contiene reglas de negocio específicas de la aplicación. Encapsula e implementa todos los casos de uso del sistema. Estos casos de uso orquestam le flujo de datos a y desde las entidades y dirije esas entidades a usar sus relgas de negocio de empresa para conseguir los objetivos del caso de uso.
No esperamos que los cambios en esta capa afecten a las entidades. Tampoco esperamos que esta capa sea afectada por los cambios de esternalidades como la base de datos, el IU o ninguno de los frameworks. Esta capa está aislada de tales asuntos.
Sin embargo, esperamos que cambios en la operativa de la aplicación afecten los casos de uso y por consiguiente el software de esta capa. Si los detalles de un caso de uso cambian, entonces algún código de esta capa muy probablemente sea afectado.
Adaptadores de Interfaz
El software en esta capa es un conjunto de adaptadores que convierten datos desde el formato más conveniente para los casos de uso y las entidades, al formato más conveniente para algunos elementos externos como la base de datos o la web. Es esta capa, por ejemplo, la que contendrá por completo la arquitectura MVC del interfáz gráfico de usuario. Los Presentadores, Vistas y Controladores todos pertenecen aquí. Los modelos son nada más que estructuras de datos que son pasadas desde los controladores a los casos de usuario y devuelta desde los casos de uso a los presentadores y vistas.
Similarmente, los datos son convertidos en esta capa, desde los más convenientes para entidades y casos de uso, en la forma más conveniente para cualquier framework de persistencia que sea usado. Por ejemplo: la base de datos. Ningún código dentro de este círculo debe saber nada de la base de datos. Si la base de datos es una base de datos SQL, entonces todo el SQL debe estar restringido a esta capa y particularmente a esta capa que tiene que trabajar con la base de datos.
También en esta capa se encuentra cualquier adaptador necesrio para convertir datos desde alguna fuente, como un servicio externo, para la forma interna usada por caso de uso y entidades.
Frameworks y Drivers
El capa más externa es generalmente compuesta por frameworks y herramientas tales como la base de datos, el framework web, etc. Generalmente no sueles escribir mucho código en esta capa otro que pegamento que comunica con el siguiente circulo interno.
Esta capa es donde todos los detalles van. La web es un detalle. La base de datos es un detalle. Mantenemos estas cosas fuera donde pueden hacer poco daño.
¿Sólo cuatro cículos?
No, los círculos son esquemáticos. Puedes necesitar más de estas cuatro capas. No hay ninguna regla que diga que debas usar siempre estas cuatro capas. Sin embargo, La Regla de Dependencia siempre se aplica. la dependencias de código fuente siempre apuntan hacia adentro. Cuanto más adentro, más aumenta el nivel de abstración. El círculo más externo es muy bajo en detalles contretos. Al moverte hacia adentro el software aumenta su nivel de abstración y encapsula políticas de más alto nivel. El círculo interno es el más general.
Cruzando límites
En la esquina inferior derecha del diagrama hay un ejemplo de como cruzamos los límites de los círculos. Muestra a los Controladores y Presentadores comunicando con los Casos de Uso de la siguiente capa. Fíjate el control de flujo. Empieza en el controlador, se mueve a través del caso de uso y concluye la ejecución en el presentador. Comprueba también las dependencia de código fuent. Cada una de ella apunta hacia adentro hacia los casos de uso.
Usualmente resolvemos esta aparente contradicción usando el Principio de Dependencia Inversa. En un lenguaje como Java, por ejemplo, organizaríamos interfaces y relaciones de herencia tales que las dependencias de código fuente se opusieran la control de flujo en los puntos correctos a través de los límites.
Por ejemplo, considera que el caso de uso requiera llamar al presentador. Sin embargo, esta llamada no debe ser directa porque violaría La Regla de Dependencia: Ningún nombre el un círculo externo debe conocer puede ser mencionado en un círculo interno. Así pues tenemos que el caso de uso invoca un interfaz (Mostrado aquí como Use Case Ouput Port) en el cículo interno y tiene el presentador en el circulo externo que lo implementa.
La misma técnica es usada a través de todas las fronteras en la arquitectura. Aprovechamos el polimorfismo dinámico para crear dependencias de código fuente que se opongan al control de flujo de tal manera que podamos cumplir La Regla de Dependencia no importa qué dirección lleve el control de flujo.
Qué datos cruzan las fronteras
Típicamente los datos que cruzan las fronteras son estructuras de datos simples. Puedes usar estructuras básicas o simples objetos de Transferencia de Datos que prefieras. O los datos puedan ser simplemente argumentos de funciones. O puedes empaquetarlos en mapas o contruirlos como objeto. Lo importante es que solo pase a travé de las fronteras datos independientes y simples. No queremos hacer trampa y pasar Entidades o filas de base de datos. No queremos que las estructuras de datos de ningún tipo violen La Regla de Dependencia.
Por ejemplo, muchos frameworks de bases de datos devuelven datos formateados como respuesta a una petición. Podríamos llamar a esto EstructuraDeFila. No queremos pasar esa estructura de fila dentro a traves de una frontera. Eso violaría La Regla de Dependencia porque forzaría al círculo interno a conocer algo acerca de un círculo externo.
Por lo que cuando pasamos datos através de fronteras, siempre debe ser en la forma más conveniente para el círculo interno.
Conclusión
Aplicar estas simples reglas no es difícil y te pueden ahorrar muchos dolores de cabeza en el futuro. Separar el software en capas y aplicando La Regla de Dependencia, puedes crear un sistema que sea testeable inrinsecamente, con todos los beneficios que implica. Cuando alguna de la partes externas quede obsoleta, como la base de datos o el framework web, puedes reemplazar estos elementos obsoletos con un mínimo de jaleo.