Pipeline vs S2S: Architecting for Control in Voice Local AI
Why the Modular Pipeline is the Engine of Production Voice AI
In the rapidly evolving landscape of Speech-to-Speech (S2S) models, the temptation to move toward “native” multimodal models is strong. However, for building robust, production-ready systems, the Modular Pipeline (STT -> LLM -> TTS) remains an engineering powerhouse.
While S2S offers a glimpse into the future of natural interaction, the Modular Pipeline provides the control, flexibility, and hardware-agnosticism required to build professional software.
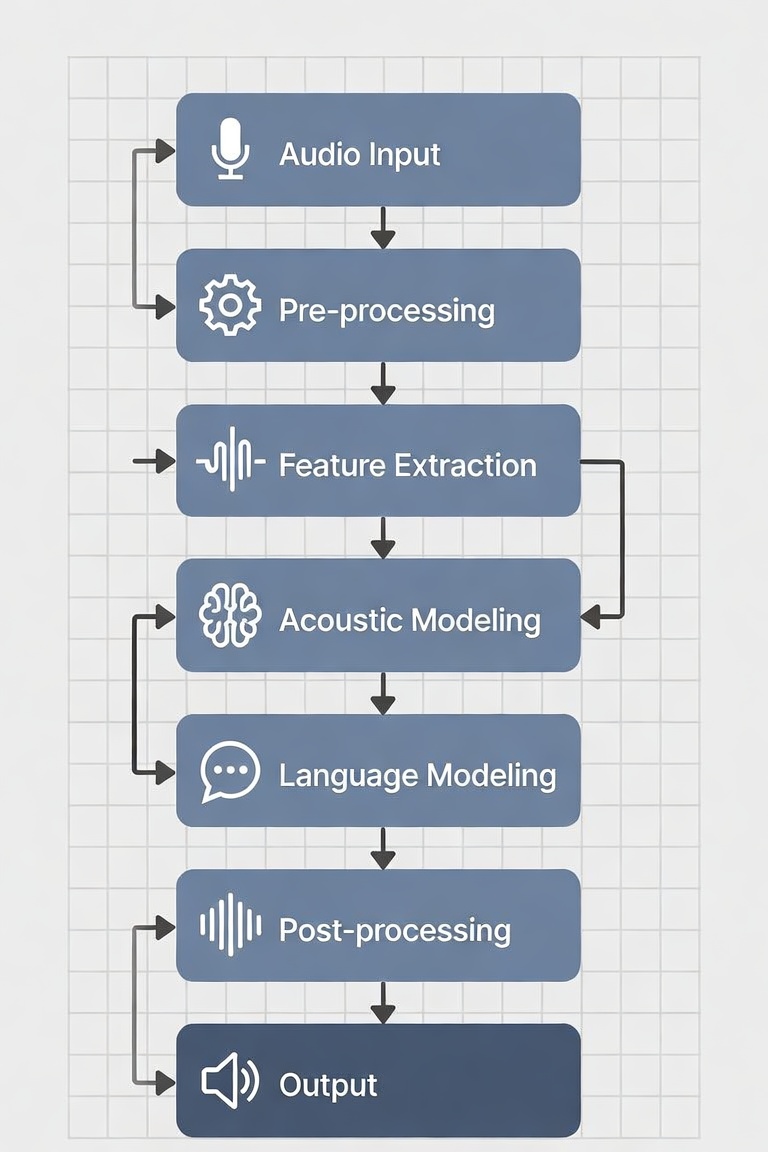
The Power of Modular Flexibility
The primary reason for choosing a Pipeline architecture is the ability to decouple components. In AI, the “state-of-the-art” changes every week. A modular approach allows for:
- Hot-swappable Models: Need a faster STT for a specific region? Swap it. Want to use a smaller, local MoE model for low-latency reasoning? Swap the LLM.
- Hardware Heterogeneity: AI is not a monolith. A production environment might span from Mac Minis (optimized for different architectures) to DGX clusters with high-end CUDA support. A pipeline allows you to optimize each step for the specific hardware it runs on.
Resource Efficiency: The Key to Local Deployment
One of the most critical advantages of the Pipeline is its footprint. A native S2S model must handle voice decoding, LLM reasoning, and audio synthesis simultaneously, often resulting in a model size and compute requirement nearly equal to the sum of all three components.
In a Pipeline, tasks are decoupled. The STT can run independently while the LLM and TTS are idle, significantly lowering the hardware overhead for that specific task. While the LLM and TTS may overlap during generation, this can be minimized by using short-response prompts.
This surgical separation of concerns is what makes running a high-quality Voicebot on your own hardware—privately and locally—feasible. It allows for a level of optimization that monolithic models simply cannot match.
The “Intermediate Space”: The Hidden Superpower
One of the most overlooked advantages of the Pipeline is the “space” between the STT and the LLM. This isn’t just a latency cost; it’s a processing opportunity. By intercepting the text stream, we can perform:
- Speaker Identification: Knowing who is talking before the LLM even sees the prompt.
- Keyword Forcing: Identifying specific triggers (like “search” or “investigate”) to force specific tool calls or logic paths.
- Wakeword Management: Implementing robust wake-up logic that is nearly impossible to handle reliably in a continuous S2S stream.
Engineering for Immediacy: Beating the Latency Gap
To compete with native S2S latency, we employ three specific engineering tactics that maximize the efficiency of the Pipeline:
1. Concurrent Transcription
For the STT to be truly efficient, transcription must occur while the user is speaking. The objective is to have the text ready by the moment the Voice Activity Detection (VAD) identifies the end of speech. This requires an STT model capable of keeping pace with human speech in real-time, ensuring the system doesn’t feel like it’s “waiting” for the user to finish.
2. Prioritizing Time to First Token (TFTT)
In our architecture, the paramount metric for the LLM is TFTT. Because user prompts are typically concise, high throughput (Tokens Per Second) is less critical than starting the response immediately. A steady 50 tokens/s is more than sufficient because we don’t need to generate massive paragraphs instantly; we just need to start the “flow” of conversation as quickly as possible.
3. The Immediacy Tricks
We use two clever tricks to create a sense of instantaneity:
- Prompt Engineering: We instruct the LLM to begin its responses with short, affirmative anchors like “Yes,” “Agreed,” or “Let’s go.” This provides an immediate conversational hook.
- Sentence Parsing: We implement a parser that splits the LLM’s text stream by punctuation (commas and periods). As soon as the parser detects a complete phrase, it fires the TTS engine. This allows the system to start speaking the first part of the answer while the LLM is still generating the remainder of the message.
Handling the “Human” Side: Barge-in and Emotion
A common critique of the Pipeline is the loss of emotional prosody and the latency of sequential steps. However, these are solvable engineering problems:
- Barge-in: Because we manage the threads, we can instantly kill a TTS playback or an LLM generation the moment the STT detects the user has started speaking again. This is crucial for natural flow.
- Emotion Tagging: We don’t need a native S2S model to “feel” emotion. By using an STT that detects sentiment and passing that as a metadata tag (e.g.,
[User](sad) I don't know what to do today), the LLM can still generate a contextually aware, empathetic response.
Conclusion
S2S is a marvel of research, but the Pipeline is a masterclass in engineering. It trades a small amount of native latency for a massive amount of control, debuggability, and production reliability. For anyone building a Voicebot that needs to do more than just “chat”—that needs to act—the Pipeline is the way to go.
Follow the project on Twitter: Voicebot updates